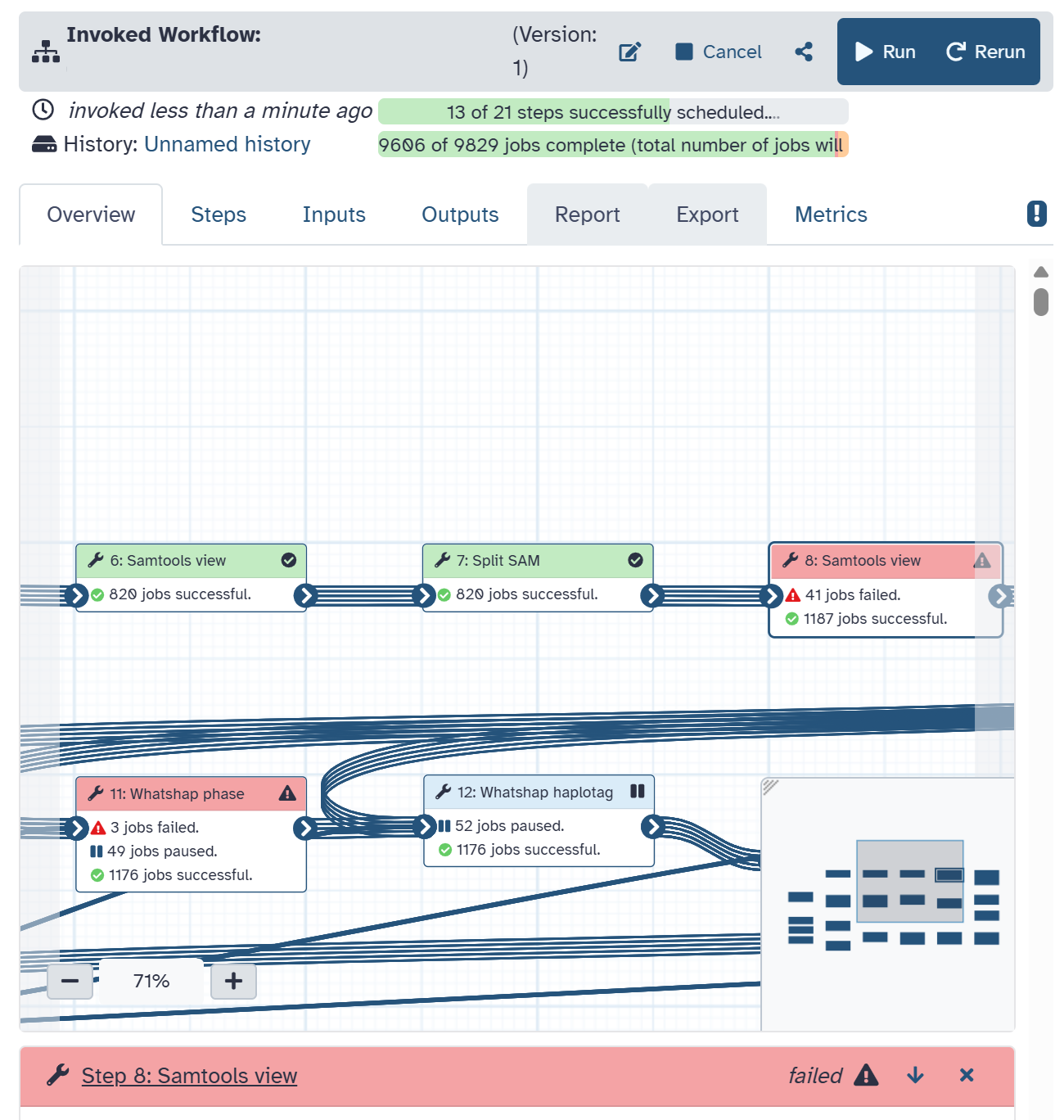
I’m running some massive workflows on a private Galaxy instance, with up to thousands of individual jobs. Occasionally it might happen that jobs crash - this is now I fear due to very short lasting lost communication with the cluster for whatever reason. Anyhow, I’m struggling to figure out how to re-submit these crashed jobs rather than having to run the whole time-consuming workflow again.
I assume it’s possible since some jobs have now reached a ‘pause’ state - waiting for it’s dependencies to finish first.
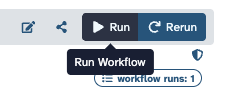
Does anyone know? Presumably it’s either the Run / Re-run buttons (and perhaps subsequent settings) but I don’t understand the difference between them.
Yes, you can rerun just the jobs that failed, replace the result back into the original set of outputs, then resume downstream tools that use those inputs. This is a per-dataset level action instead of workflow.
Why? There isn’t a good way to only fetch only the prior failures and rerun them again from a Workflow Invocation since there are some (advanced!) complications with how a workflow invocation attaches to individual prior scheduled or completed jobs. We are still thinking about solutions. For now, you can get all original inputs (again) and rerun the batch but I’m guessing this is not what you want right now.
Dataset controls (at the history level)
Workflow controls (at the invocation level)
Then, for this part, the icons in your screenshot are for the workflow level, not individual jobs (and the datasets those are started from or written to).
The workflow Run button will load up the original workflow form again (where you can select the inputs based on the current history).
The workflow Rerun button will run that entire invocation over again – exactly. You’ll see a pop-up to switch to the original history again if needed (to allow the workflow to automatically select the same inputs and output data/settings again).
So, for now, to pick up only the current failures without rerunning the entire processing again: click into the output history and rerun the individual datasets using the optional items to replace/resume.
If you are the server administrator, you can also go in and start up jobs directly via the API. This involves scanning for failed job over a particular time period and rerunning them. I can share more details if you want to try this instead and are not sure where to start.
In addition to all of the above, if, in a high-throughput scenario, you have a lot of failed jobs that can, in principle, be resumed, but it’s just very annoying to do this job by job through the UI:
the planemo command line tool can automate this process for you as explained here:
Thanks for the amazing detailed answer. I’m fine with manually re-running the failed jobs, happy to know that dependencies will resume from there on. I’ll try it tomorrow!