Hello, I am using kraken2 on the galaxy Europe server to assign taxonomic labels to shotgun sequencing reads. I created a paired end list of the samples and then used trimmomatic to trim reads. I then used the trimmomatic paired output collection as the input for my Kraken2 analysis. When I run the tool some samples turn red and return the following error message “FATAL: container creation failed: mount hook function failure: mount /data/dnb12/galaxy_db->/data/dnb12/galaxy_db/ error: while mounting /data/dnb12/galaxy_db: mount source /data/dnb12/galaxy_db doesn’t exist”. The rest of the samples turned green. I have tried rerunning the tool and noticed that different files turn red each time, so the problem must not be the files. Is there an issue with Kraken2 at the moment? Or is there some settings that I need to change? Thanks for your assistance.
Hi @bgood07
As a first pass guess, the EU server was likely just busy over the weekend.
I can see a window where many Kraken2 jobs were running all at the same time in the job statistics.
Graphics for the current version of Kraken2 for the last two days:
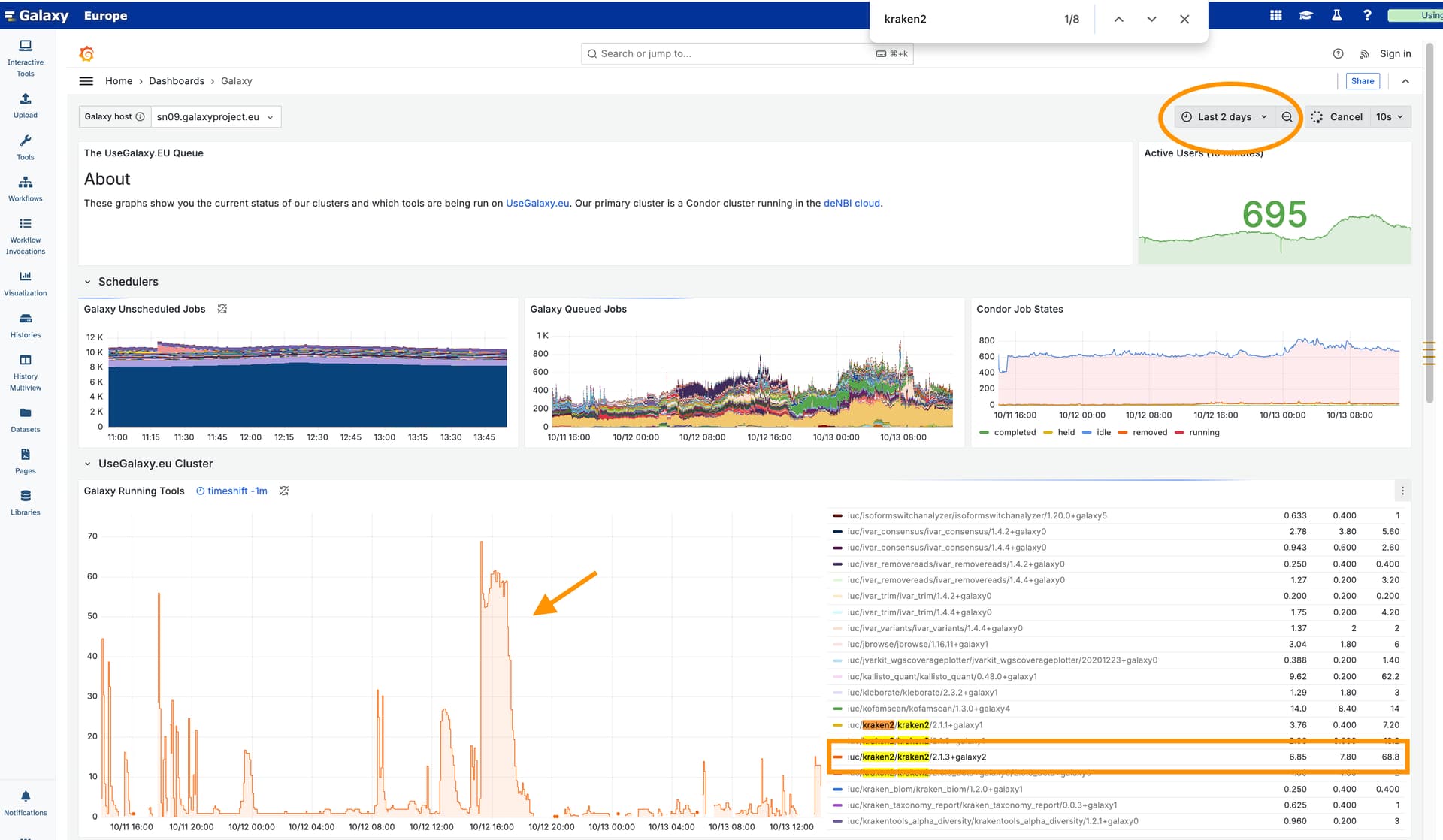
There isn’t anything you can do on your side to get this to process in parallel differently, but I’m wondering if the EU administrators would be interested in reviewing to see if something should be adjusted on the server re concurrent jobs accessing that same shared resource. Or, maybe there was some other small known issue impacting the work. Let’s ping them here – Hi @wm75, what do you think?
What to do
Then, the advice I would have for larger batches of work at the public servers. 1. start up the processing for an entire batch. 2. Later, if some fail, click into the collection and use the rerun icon on each failed dataset. This brings up the original tool form and you can run it again for just that single sample.
Bonus: If the failed job was run as part of a workflow, right above the Run Tool button will be two new extra options. This is useful when running longer, complicated workflows, but also shorter ones. The result is indistinguishable from runs where everything worked perfectly to start with.
- Replace elements – this sorts the new output back into the original collection output nesting (with the already successful inputs).
- Resume dependencies – this starts up any downstream tools that were paused because of these upstream failures (assuming the new job works!)
For you or anyone reading interested in workflows: these can contain as few as one tool (plus the “inputs” definition). These don’t have to be created from scratch and can instead be templated by extracting from existing histories. This simple tutorial has a short example if interested → Hands-on: Galaxy Basics for everyone / Galaxy Basics for everyone / Introduction to Galaxy Analyses (Galaxy Management)
Let’s start there and please let us know if you have follow up questions. The EU admins may also appreciate a shared history here but they can find the jobs other ways too – you could send in a bug report from one of the failures and put a link to this topic in the comments form to link it all back together for extra context. Hope this helps! ![]()
As you guessed I think it’s the server. I was able to get kraken2 to work for all my samples. However, now I am having the same issue with bracken.
Currently, I have all my samples in a collection. So when a few turn red, I then can’t put this collection through the krakentools for calculating alpha and beta diversity. I’ve tried rerunning the red samples, and they successfully run but then I can’t replace them in the collection.
I will try to find a similar workflow to see if the method you mentioned works. Thanks.
Hi @bgood07
Yes, a workflow would allow you to replace anything that fails.
Some workflow suggestions
IWC workflow – this one is doing exactly what you are for some steps. You can remove any tools you don’t need. All of this happens in the web browser and please ask questions if you get stuck.
or
Extract a workflow – everything in the active history will be included by default, but you can deselect any tools you don’t need. Or, copy the datasets into a new clean history, run the tools you want, and extract from there (two samples would be enough to create the template). Then once in the Editor, make adjustments by adding/removing as wanted.
This is a short example! Search the site with “workflow” to find much more but those are mostly a reference – you’ll see how this works quickly once in the view.
Hope this helps! You are still welcome to share your history back for more specific feedback. ![]()